 IT Tutorial IT Tutorial | Oracle DBA | SQL Server, Goldengate, Exadata, Big Data, Data ScienceTutorial
IT Tutorial IT Tutorial | Oracle DBA | SQL Server, Goldengate, Exadata, Big Data, Data ScienceTutorial
Online redo log files are files that hold transaction records in the database. Log files to recover the database in case of a problem.
For example, if we shut down the database abruptly (shutdown abort), SMON performs instance recovery by reading these log files during database startup.
There must be at least two online redo log groups in a database and each redo log group must have at least one online redo log member.
When the database is first created, 3 online redo log groups are created by default. Control files are the same, but redo log files are different files.
Usually we back up Control files against any problem, similarly we need to increase the number of redo log members of redo log group, we should also store each online redo log member on separate disks.

The LGWR background process is responsible for sequentially writing processes in the redo log buffer area in memory to online redo log files.
The redo log group actively written by the LGWR process is the “current” online redo log group. The LGWR process writes transactions to the online redo log group while simultaneously writing to all redo log members in that group.
The database must successfully write to at least one redo log member in the redo log group in order to proceed successfully.
When the “Current” online redo log group is full, the LGWR process continues to write to the next online redo log group. When the last online redo log group is full, it continues to overwrite the first redo log group again.

This is not preferred in production databases. Because the redo log group operations cannot be recovered when you need to recover the database.
Each transaction in the database is very important to us. Therefore, the database must be in archive mode.
In a database in archive mode, when the 1st redo log group is full, the ARC background process creates a copy of the 1st redo log group. This copy file created is called archive log file.
Then the “log switch” operation takes place and LGWR starts to write to the 2nd redo log group.
When the second redo log group is full, the ARC background process creates a copy of the second redo log group. Then the “log switch” operation takes place and LGWR starts to write to the third redo log group.
This process continues in the form of a loop.
Redo log groups must be backed up by the ARC process as an archive log file. Redo log groups on the operating system cannot be backed up by file copying.

NOTE:
The log_archive_dest_1 parameter is used to save the archive log files created in a database in archive mode. If desired, a second location can be given by log_archive_dest_2.
If this parameter is not set, archive log files are saved under $ ORACLE_HOME / dbs in Linux environments by default.
The status of our online redo log groups may be as follows in the v $ log view,
SELECT a.group#, a.member, b.status, b.archived, bytes/1024/1024 mb from v$logfile a, v$log b where a.group# = b.group# order by 1;

Current: Indicates that the online redo log group is currently being written by the LGWR process.
Active: Redo indicates that the log group is required for crash recovery. The Redo log group can be archived or unarchived.
Inactive: Indicates that the Redo log group is not required for crash recovery. The Redo log group can be archived or unarchived.
Clearing: redo log group is cleared with “ALTER DATABASE CLEAR LOGFILE”
Unused: The Redo log group has just been created and has not yet been used.
One of the important points of the online redo log is the managed size of the files
By default, 50MB is created in the database setup. We can change the size of redo log files during and after installation.
If the size of online redo log files is small in a highly transactional database, the “log switch” process is frequently performed.
This will slow down our operations.
v$log_history provides us with information about how often online redo log groups switch. We can analyze these time intervals with the following query.,
SELECT COUNT (*), to_char (first_time, 'dd:mm:yy:hh24') from v$log_history group by to_char(first_time, 'dd:mm:yyyy:hh24') order by 2 desc;
With the above query, we can find out at what time interval “log switch” is performed. At that time interval, the database can also examine running processes.
It is not good to keep the size of the Redo log file too high. Because the log switch operation will be delayed.
NOTE:
With the ARCHIVE_LAG_TARGET parameter, we can determine how many seconds the database will make a log switch.
The default is 1800 seconds. The online redo log group is automatically switched on at 30 minutes, even if it does not fill for 30 minutes.
Each time a log switch is performed, a checkpoint is also performed. When the checkpoint is executed, the dirty / modified blocks in the DBWR database buffer cache are written to the data files located on the disk.
Before the LGWR process overwrites a redo log group, all modified (dirty blocks) blocks in the database buffer cache associated with that redo log group must be written to the data files.
If not all of the changed blocks are successfully written to the data files, we encounter an error in the alert file as follows.
Thread 1 cannot allocate new log, sequence 204
Checkpoint not complete

The point to consider when increasing the number of online redo log groups is the value of the MAXLOGFILE parameter that we use when creating the database.
If we exceed this value, we must rebuild our control file by increasing the value of the MAXLOGFILES parameter.
The other parameter to be considered is FAST_START_MTTR_TARGET.
When we keep the value of this parameter low, the DBWR process writes dirty blocks more often into the data file. This parameter is applicable when the database is open.
Another parameter is DB_WRITER_PROCESSES
We can determine the number of DBWR process with this parameter. For this parameter to be valid, the database must be closed and opened.
ADD ONLINE REDO LOG GROUP
To add an online redo log group, we use the SQL statement “ADD LOGFILE GROUP“.
ALTER DATABASE ADD LOGFILE GROUP 7 (‘+DATA/TESTDB/ONLINELOG/redotest.log’) SIZE 1024M;
select GROUP#,TYPE,MEMBER from v$logfile;
DELETING ONLINE REDO LOG GROUP
When deleting a redo log group, its status MUST be “INACTIVE“.
ALTER DATABASE DROP LOGFILE GROUP 3;
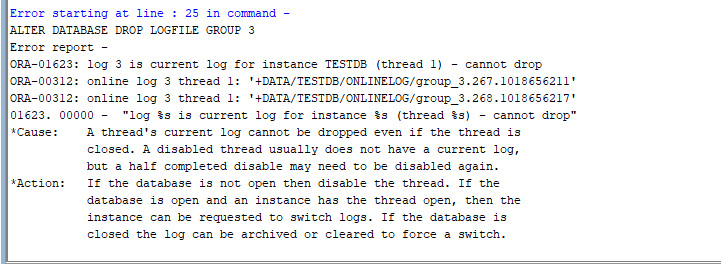
If you try to delete the currently used online redo log group whose status is “current”, we will see an error in the image. In this case, we can perform the “log switch” operation to ensure that the next redo log group is current.
ALTER SYSTEM SWITCH LOGFILE;

When the next redo log group is “current”, it will not be immediately “inactive” if the leading redo log group contains redo for crash recovery.
A redo log group whose status is “ACTIVE” cannot be deleted. If you try to delete it,
ERROR at line 1:
ORA-01624: log 3 neede for crash recovery of instance TESTDB (thread 1)
ORA-00312 online log 3 thread 1: ‘+DATA/TESTDB/ONLINELOG/group_3.268.1018656217’
NOTE:
When “log switch” is performed, that redo log group is active until all modified blocks in the database buffer cache connected to the previous redo log group are written to the data file.
In this case, we perform the checkpoint operation as follows and we ensure that all modified blocks in the Database Buffer Cache for the “active” redo log group is written to the data file.
ALTER SYSTEM CHECKPOINT;
This makes the status of the online redo log group “inactive” and we can delete it.
Adding a Redo Log Member
To an existing online redo log group, the redo log file is added as follows,
ALTER DATABASE ADD LOGFILE MEMBER '+DATA/TESTDB/ONLINELOG/redo03.log' TO GROUP 3;
A different disk is recommended when adding a new redo log member.
Removing/Deleting a Redo Log Member
When deleting an online redo log member, the status of the online redo log group to which the redo log member is bound must not be “current”.
SELECT A.GROUP#, A.MEMBER , B.STATUS B.ARCHIVED, B.THREAD# FROM V$LOGFILE A, V$LOG B WHERE A.GROUP# = B.GROUP# ORDER BY 1, 2

If the status is not “current”, we can delete the redo log member as follows,
ALTER DATABASE DROP LOGFILE MEMBER '+DATA/TESTDB/ONLINELOG/group_1.263.1018656191';
See you in the next article..
Do you want to learn Oracle Database for Beginners, then read the following articles.
https://ittutorial.org/oracle-database-19c-tutorials-for-beginners/