 IT Tutorial IT Tutorial | Oracle DBA | SQL Server, Goldengate, Exadata, Big Data, Data ScienceTutorial
IT Tutorial IT Tutorial | Oracle DBA | SQL Server, Goldengate, Exadata, Big Data, Data ScienceTutorial


Clustering Wikipedia Hi, in this article i’ll make a simple clustering example using wikipedia. You …
Read More »

Recent Posts
April, 2026
- 1 April
Kessbet Online
Kessbet Online Casino offers a modern, interactive platform for online gaming enthusiasts, blending entertainment with strategic gameplay. The website hosts a wide variety of games, including slots, card games, and …
Read More » - 1 April
Digital Architecture and Analytics in Online Casino Apps
WinWin (winbetin) Online Casino Login provides users with a seamless digital platform for engaging casino experiences. The system integrates advanced security protocols, ensuring that player data and transactions remain safe …
Read More »
March, 2026
- 31 March
Experience the Best of Kenyan Online Entertainments
Odibet Online Casino Kenya has become a go-to destination for players looking for a safe, exciting, and user-friendly gaming experience. The platform offers a wide variety of games, including slots, …
Read More » - 31 March
Experience Exciting Games and Bettings Safely
Marakumi Casino has evolved into one of the most exciting online gaming destinations, offering a variety of games that cater to every type of player. From classic slots to table …
Read More »
December, 2021
- 13 December
Elements of a Good Developer Portal
A developer portal can be defined as the interface standing between a set of SDKs, APIs, and other interactive tools and applications. The portal is responsible for helping organizations achieve …
Read More »
November, 2021
- 10 November
The Best Tips for Choosing High-Quality IPTV services

Before choosing the best iptv services for your system, it is essential to know what IPTV is and what it stands for. IPTV is the acronym of Internet Protocol Television. …
Read More »
October, 2021
- 18 October
DATA WAREHOUSE – ODS (OPERATIONAL DATA STORE)

ODS (Operational Data Store) ODS (Operational Data Store) is the database where all the source tables you need are stored in the live database. It is often used for data …
Read More »
September, 2021
- 7 September
DATA WAREHOUSE – OLTP/OLAP
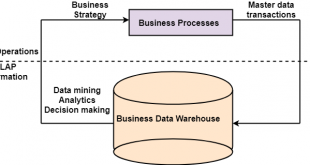
OLTP (On-line Transaction Processing) By the mid-1970s, online transaction processing (OLTP) made even faster access to data possible, opening whole new vistas for business and processing. Shortly after the advent …
Read More »
July, 2021
- 26 July
Why low-code development platforms are gaining increasing popularity?

What does it take to create a business app? A large budget, a team of skilled developers, and plenty of time and patience, one might argue, but it’s exactly this …
Read More » - 7 July
MapR Hadoop Distribution For Managing Big Data and Step by Step Mapr Cluster Install In The Best Way

Subjects Bigdata Manage What is Hadoop? Why is Hadoop important? What is MapR Hadoop Distribution Why you should choose MapR Hadoop distribution? What are Services? Steps Deploy Mapr Cluster Mapr …
Read More »
February, 2021
- 27 February
DATA WAREHOUSE – CHANGE DATA CAPTURE (CDC)

CDC (Change Data Capture) It can be called the process of defining and capturing changes made in the database. It is also referred to as a design pattern to identify …
Read More » - 1 February
Kafka Stream API Json Parse

Kafka Stream API Json Parse Hello, in this article, I will talk about how to process data incoming to Kafka queue with Kafka stream api. We can send data from various …
Read More »
November, 2020
- 17 November
PySpark Makina Öğrenmesi (PySpark ML Classification Decision Tree)

PySpark Makina Öğrenmesi (PySpark ML Classification) Merhaba PySpark yazılarına devam ediyoruz. Bu yazıda classification algoritmalarından Decision Tree (Karar ağacı) ile örnek yapacağız. Bu yazıya geçmeden önce bir önceki yazıyı okumalısınız. …
Read More » - 17 November
PySpark Makina Öğrenmesi (PySpark ML Classification Preapering)
PySpark Makine Öğrenmesi PySpark Makina Öğrenmesi (PySpark ML Classification) Merhaba, PySpark yazılarına devam ediyoruz. Bu yazıda pyspark kullanarak ML modeli geliştireceğiz. Bu yazıya geçmeden önce bir önceki yazıyı …
Read More » - 16 November
PySpark Makine Öğrenmesi
PySpark Makine Öğrenmesi Merhaba, bu yazı serisinde PySpark kullanarak ML uygulamaları gerçekleştireceğiz. PySpark’ı python ile spark işbirliği olarak düşünebiliriz. Python dili ile Spark üzerinde geliştirme yapabilme imkanı tanıyor. Spark kurulumuna …
Read More »
October, 2020
- 21 October
DATA WAREHOUSE – ETL/ELT

What is the ETL / ELT? ETL or ELT is not a software abbreviation. It is the most important and complex stage of the data warehouse. ETL (Extract, Transform, Load) …
Read More » - 20 October
Advanced RDD Actions
Advanced RDD Actions reduce() action reduce(func) action is used for aggregating the elements of a regular RDD. The fucntion should be commutative (changing the order of the operands does …
Read More » - 14 October
PySpark RDD Example
PySpark RDD Example Hello, in this post we will do 2 short examples, we will use reducebykey and sortbykey. Rdd = sc.parallelize([(1,2), (3,4), (3,6), (4,5)]) # Apply reduceByKey() operation on …
Read More » - 13 October
Introduction to PySpark RDD
Introduction to PySpark RDD In this chapter, we will start with RDDs which are Spark’s core abstraction for working with data. What is RDD RDD = Resilient Distributed Datasets …
Read More » - 13 October
Introduction to Big Data analysis with Spark
Hello, we’ll be introducing Spark in this series of articles. Spark can also be developed with many programming languages. We will use python in our series of articles. Introduction to …
Read More »
September, 2020
- 25 September
Analyzing Social Media Data in Python -1

Analyzing Social Media Data in Python Welcome to analyzing social media data with python. In this tutorial series we’re going to analyze Twitter data using Python. There are millions of …
Read More » - 20 September
Clustering Wikipedia

Clustering Wikipedia Hi, in this article i’ll make a simple clustering example using wikipedia. You can access full code, here: https://drive.google.com/drive/folders/1FKAqwAvaSmEt0jzL3lHu5qQGEcw4FQGS?usp=sharing # Perform the necessary imports from sklearn.decomposition import TruncatedSVD …
Read More » - 19 September
Dimension reduction with PCA | Python Unsupervised Learning -6
Dimension reduction with PCA Dimension reduction represent the same data using less features and is vital for building machine learning pipelines using real-world data. PCA performs dimension reduction by …
Read More » - 18 September
Introduction of DATA WAREHOUSE-What is DATA WAREHOUSE?

What is the Data Warehouse? A data warehouse is a repository that can be made of questioning and analysis of related data. The data warehouse has been created in order …
Read More » - 18 September
Dimension reduction | Python Unsupervised Learning -5
Hello, in this article, we continue the topic Unsupervised Learning.
Read More »